
Extracting Word Embedding & Sentence Embedding From BERT
Published:
Natural Language Preprocessing (NLP) is booming and rapidly increasing for a few years now. Picking an NLP model is not as hard as a few years before, since many models are currently developed by many NLP communities out there and can be freely downloaded and used in your model. That’s why our conceptual understanding of how is the best way to represent words and sentences is more important. Google’s BERT (Bidirectional Encoder Representation from Transformer) is one of the well-known models that have been used in a lot of research and projects.
Word Embeddings
Embedding is a relatively low-dimensional space into which you can translate high-dimensional vectors. Embedding is a vector representation of words. By changing words into the embeddings it becomes easier for the model to get the semantic importance of a word in numeric form and can perform mathematical operations on it. BERT has embeddings that were contextualized by words and sentences. So, we need to understand what is word embeddings.
DistilBert
Transfer Learning approaches in Natural Language Processing (NLP) with large-scale pre-trained language models have become a basic tool in many NLP tasks. While these models have significant advantages, they often also have loads of parameters. These in turn lead to several downsides such as bigger environmental costs and the growing computational and memory requirements that may hamper wide adoption.
A method to pre-train a smaller general-purpose language representation model called DistilBert can be tuned with good performances on a much wider scale to overcome this. DistilBert is an improved version of Bert. Both more or less have the same general architecture in which the token-type embeddings and the pooler are removed while the number of layers is reduced. If simplified, Bert architecture will look like these
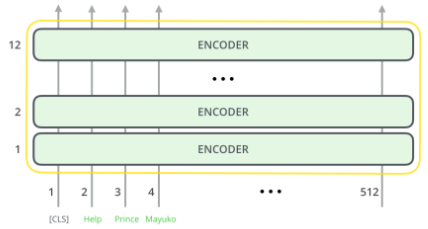
For the input, BERT can except three inputs that we can choose the token input, token input, and other input, or all the inputs. The illustration of BERT’s expectations is down below.
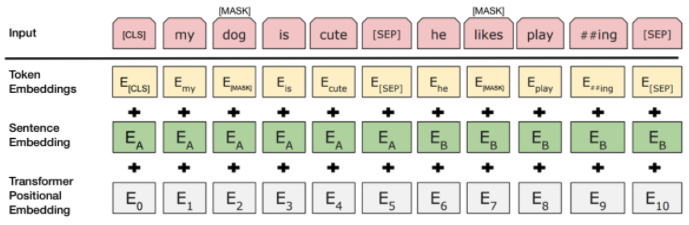
The input layer is simply the vector of the sequence tokens along with the special tokens. For example, The “##ing” token is the product from splitting tokens like “playing” to “play” and “##ing”. This is because BERT utilizes WordPiece [6] to cover a wider spectrum of Out-Of-Vocabulary (OOV) words. Token embeddings are the vocabulary IDs for each of the tokens. Sentence Embeddings is just a numeric class to distinguish between sentences A and B. And lastly, Transformer positional embeddings indicate the position of each word in the sequence.
DistilBert is distilled in very large batches leveraging gradient accumulation using dynamic masking and without the next sentence prediction objective. Distillation itself is a compression technique in which a compact model (the student) is trained to reproduce the behavior of a larger model (the teacher) or an ensemble of models. Hence, DistilBert can reduce the size of a BERT model by 40% and speed up the process by 60% while retaining 97% of its language understanding capabilities.
Word Embedding Extraction with BERT
For extracting the word embeddings with BERT we need the last layer only of the BERT model with the following text using PyTorch framework. For preparing the model we need some functions to help the process.
In this case, we will choose the token ids and masks input for the BERT input, so we need to create the functions to change the sentences to BERT input.
def create_input(text, tokenizer, max_length):
stokens = tokenizer.tokenize(text)
stokens = ["[CLS]"] + stokens + ["[SEP]"]
input_ids = get_ids(tokenizer,stokens, max_length)
input_masks = get_masks(stokens, max_length)
input_ids = torch.tensor([input_ids])
input_masks = torch.tensor([input_masks])
return stokens, input_ids, input_masks
def get_ids(tokenizer, token, max_length):
token_ids = tokenizer.convert_tokens_to_ids(token)
input_ids = token_ids + [0]*(max_length - len(token_ids))
return input_ids
def get_masks(tokens, max_length):
if len(tokens)>max_length:
raise IndexError("Token length greater than max length")
return [1]*len(tokens) + [0]*(max_length - len(tokens))
After being done changing the sentences we need to extract the embeddings with the pre-trained BERT last layer.
def get_bert_embeddings(tokens_tensor, masked_tensors, model):
with torch.no_grad():
outputs = model(tokens_tensor, masked_tensors)
hidden_states = outputs[2][1:]
token_embeddings = hidden_states[-1]
token_embeddings = torch.squeeze(token_embeddings, dim=0)
list_token_embeddings = [token_embed.tolist() for token_embed in token_embeddings]
return list_token_embeddings
If succeded, it will result in the embeddings of the sentences. And then we can do anything from classification, clustering, and regression.
Conclusion ——
Since the NLP field was rapidly evolving, we need to understand how the NLP works. We can achieve that by understanding word embeddings. With many of the models developed by NLP communities, BERT is one of the most common and most used models. So we can learn how the NLP model in word embeddings work with the pre-trained BERT model.
